
CACE: Why Every AI Change Breaks Your System (And What to Do About It)
Key Takeaways:
- The Principle: CACE — "Changing Anything Changes Everything" — means AI systems lack the modular boundaries of traditional software, so any single tweak ripples unpredictably across the entire system.
- The Reality Check: Actual ML code accounts for just 5% of the infrastructure required to keep an AI system running in production.
- The Data: Databricks' 2026 State of AI Agents report shows organizations with unified governance ship 12x more AI projects to production, and those with systematic evaluation ship 6x more.
- The Recommendation: Stop treating each AI deployment as a bespoke project. Start building a living system with full-stack ownership, which is exactly what aion's Nexus platform delivers.
The algorithmic sophistication of frontier foundation models, coupled with the rapid proliferation of autonomous agentic systems, has initiated a paradigm shift. However, this period of hyper-accelerated innovation has simultaneously exposed a critical, systemic vulnerability across the enterprise landscape: the operational reality of deploying these advanced systems at scale remains exceptionally fragile. The defining challenge of contemporary AI architecture is no longer algorithmic reasoning or model performance; it is system stability and sustained productization.
This systemic fragility is deeply rooted in a foundational engineering paradigm identified over a decade ago, known as the CACE principle, an acronym for Changing Anything Changes Everything. Originally formalized in Google's seminal 2015 research concerning the hidden technical debt embedded within machine learning architectures, the CACE principle dictates that AI systems inherently lack the strict abstraction boundaries and modular isolation that define traditional software engineering.
In machine learning and modern generative AI, profound entanglement ensures that a seemingly isolated modification to a single data input, a prompt template, a retrieval mechanism, or a model hyperparameter invariably triggers a cascading alteration of system-wide behavior and performance. Consequently, the actual mathematical algorithms and machine learning code constitute a microscopic fraction: a mere five percent of the total operational infrastructure required to sustain the system in a production environment.
CACE: Changing Anything Changes Everything
The most critical and enduring concept introduced in the Google research is the CACE principle. The CACE principle states that in a machine learning system, no inputs are ever truly independent of one another.

In a theoretical scenario where a machine learning system relies on a specific set of features to make a prediction, modifying the distribution of just one of those features will instantly cause the importance, the assigned mathematical weights, and the predictive influence of all other features in the system to shift unpredictably. Adding a completely new feature, or removing an existing feature, fundamentally alters the entire decision boundary of the model. The CACE principle applies not just to data inputs, but to hyperparameters, learning settings, convergence thresholds, data sampling methods, and essentially every other possible configuration tweak within the environment.
This profound entanglement creates three highly destructive, hidden technical debt vectors that plague enterprise systems:
-
Systems suffer from correction cascades: When a foundational model exhibits a flaw or bias in a specific edge case, engineering teams frequently layer a heuristic "correction" model on top of it to act as a fast, temporary patch. Over time, these temporary corrections cascade and intertwine, creating an exceptionally brittle system architecture. Because the correction layers are heavily dependent on the exact outputs of the flawed foundational model, improving or updating the foundational model will actually break the downstream correction layers, creating a perverse incentive structure that actively discourages foundational improvements.
-
Systems are severely compromised by undeclared consumers: Because machine learning predictions and outputs are frequently published to shared enterprise data lakes or message queues, other engineering teams may silently ingest these predictions as inputs for entirely different systems without establishing formal API contracts or access controls. When the original data science team updates their model to improve accuracy, they alter the output distribution, which silently and catastrophically breaks the systems of the undeclared consumers who were relying on the previous distribution patterns. This phenomenon, categorized as visibility debt, makes it extraordinarily dangerous and expensive to update models in production.
-
Organizations accumulate massive configuration debt: Over time, machine learning pipelines accumulate vast, undocumented "jungles" of configuration files that determine feature selection, data thresholds, and routing logic. This configuration debt rapidly becomes as dangerous as actual code debt, as a single misconfigured boolean flag or threshold value can degrade system accuracy globally, often without triggering traditional software failure alerts.
CACE is worse in the age of AI Agents
Because generative AI systems operate probabilistically rather than deterministically, the application of CACE to modern agentic architectures manifests in new, highly volatile domains.
| Vector of Entanglement | Mechanism of Systemic Failure | Impact on Production Systems |
|---|---|---|
| Prompt Entanglement | Prompt templates and system instructions function as highly sensitive, high-level configurations. Modifying a system prompt to fix a localized hallucination alters the stochastic attention mechanism of the entire underlying language model. | A seemingly minor textual fix designed to address a specific edge case unexpectedly degrades the agent's core reasoning capabilities across entirely unrelated workflows, breaking the system. |
| Retrieval (RAG) Entanglement | Retrieval-Augmented Generation architectures rely on semantic vector search to ground models in factual data. Modifying the embedding extraction method, altering the chunking strategy, or expanding the context window size changes the input distribution the model receives. | The model receives a different density and formatting of context, which can trigger severe regressions in task performance and instruction adherence that appear logically disconnected from the retrieval adjustment itself. |
| Tool Schema Entanglement | Autonomous agents interact with external enterprise systems via strictly defined API schemas and JSON structures. If a target enterprise API updates its schema, the agent's internal orchestration logic which was prompt-engineered to interface with the legacy schema fails to comprehend the change. | Failures propagate backward through the entire pipeline. The agent hallucinates parameters to fit the broken schema or enters an infinite loop of failed tool calls, causing downstream deterministic systems to crash. |
| Configuration Debt | Agentic configurations, including temperature settings, top-p thresholds, and multi-agent routing logic, act as undeclared dependencies within the ecosystem. | Minor adjustments to a routing threshold can result in complex queries being sent to underpowered models, leading to subtle but widespread regressions that evade basic unit testing. |
Because of these modern CACE dynamics, contemporary AI architectures are uniquely brittle. When a change occurs whether initiated intentionally by a developer updating a prompt template, or driven passively by environmental drift in user behavior and real-world data distribution, the entire socio-technical system shifts.
Evaluating and mitigating this profound entanglement requires statistically grounded evaluation pipelines that continuously monitor for regressions across the entire ecosystem whenever a single, atomic component is modified.
Insights from the 2026 State of AI Agents
The most definitive evidence of this paradigm shift comes from the "State of AI Agents" report, published by Databricks in early 2026. The report analyzed deep telemetry and usage data from over 20,000 global enterprise organizations, including more than sixty percent of the Fortune 500, providing an unprecedented look into actual production environments. The data revealed a staggering, irrefutable correlation between operational rigor and successful deployment velocity.
The report identified two critical, data-driven metrics that completely differentiate successful artificial intelligence adopters from those permanently trapped in pilot purgatory:
- The 12x Governance Multiplier: Organizations that actively implement unified AI governance — defined by the enforcement of strict policies regarding data usage, structured accountability, automated guardrails, and programmatic rate limits — push an astonishing 12 times more AI projects into production than organizations that lack these integrated structures.
- The 6x Evaluation Multiplier: Companies that utilize systematic, automated evaluation tools to continuously measure model quality and agent reasoning move nearly six times more AI systems into production.
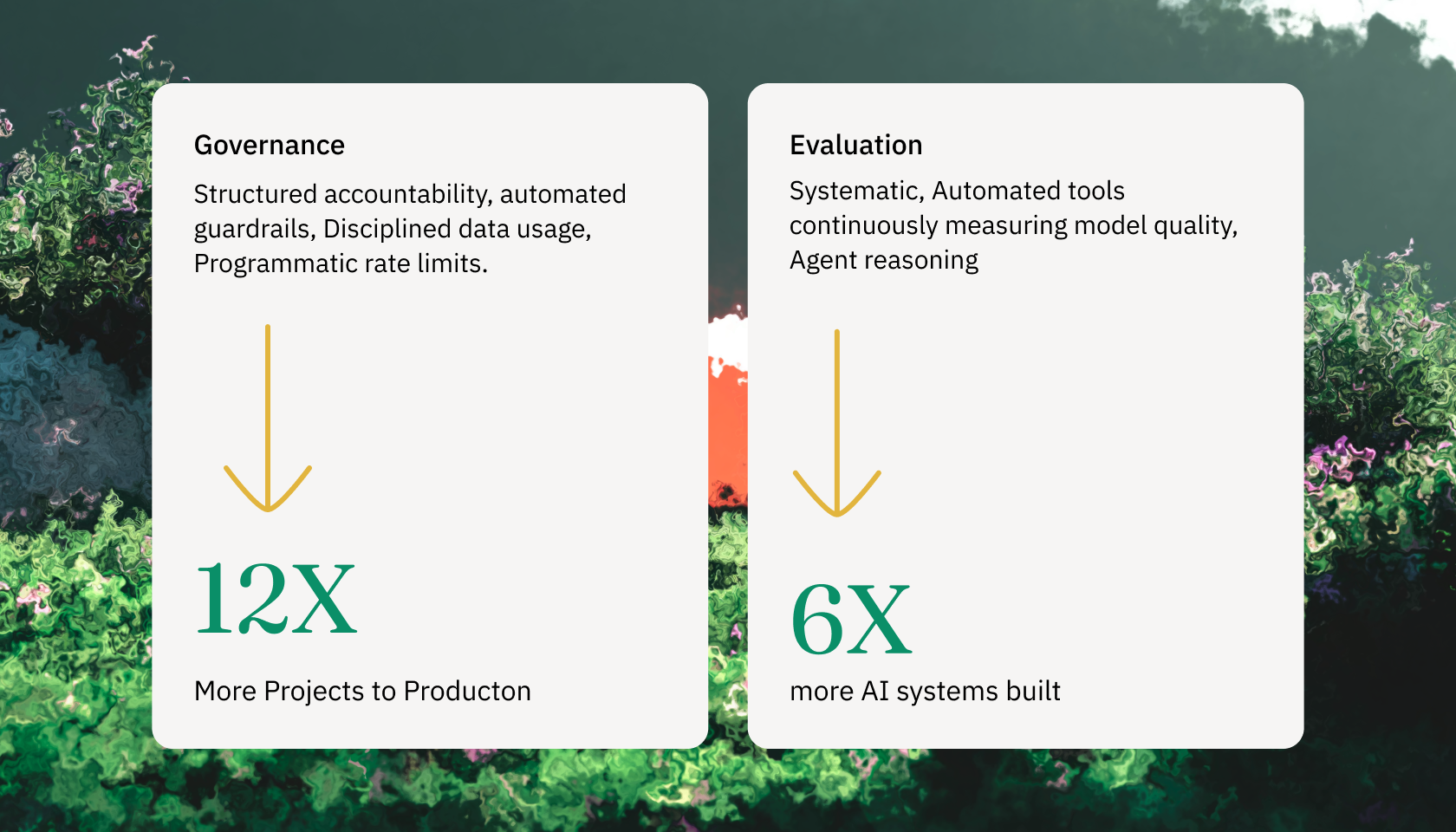
Both findings point at the same truth. You cannot tame CACE with careful engineering on a single component. The only counter to system-wide entanglement is system-wide observability and control.
Companies that scale AI don't treat each deployment as a bespoke engineering project. They invest in orchestration, model routing, governance, monitoring, and compliance infrastructure that makes deployment repeatable.
Nexus: aion's answer to CACE
You are not deploying a model, you are building a living system. That system needs full-stack ownership: continuous monitoring, automated retraining, tight feedback loops, and governance that catches entanglement failures before they reach users.
Nexus is aion's proprietary platform for building, deploying, and continuously improving production-grade AI models, workflows, and agents. Each capability maps directly to a CACE failure mode:
- Agent orchestration with state management and fallbacks, so prompt-entangled failures don't silently kill multi-step workflows.
- Intelligent model routing that sends each task to the right model at the right cost with built-in evaluation to catch regressions when routing logic drifts.
- Systematic evaluation pipelines that continuously measure reasoning quality across the ecosystem, surfacing the regressions unit tests miss.
- Human-in-the-loop governance, where every agent decision is logged, auditable, and explainable. Our forward-deployed engineers (FDEs) can review and override without writing code.
- Enterprise-grade security and compliance — role-based access, multi-tenancy, full audit trails, data residency controls — so you know exactly who is consuming what, and no undeclared consumers can creep in.

Nexus supports over 1,000 models and is designed so every deployment compounds on the last. Each customer implementation makes the platform smarter and faster for the next. This is the infrastructure layer that turns one-off deployments into a scalable AI capability.
You cannot layer AI onto a static architecture. If your system is susceptible to constant change, CACE will find it and break it in production. Let's chat.





